Writing my own media catalogue
19 Feb 2024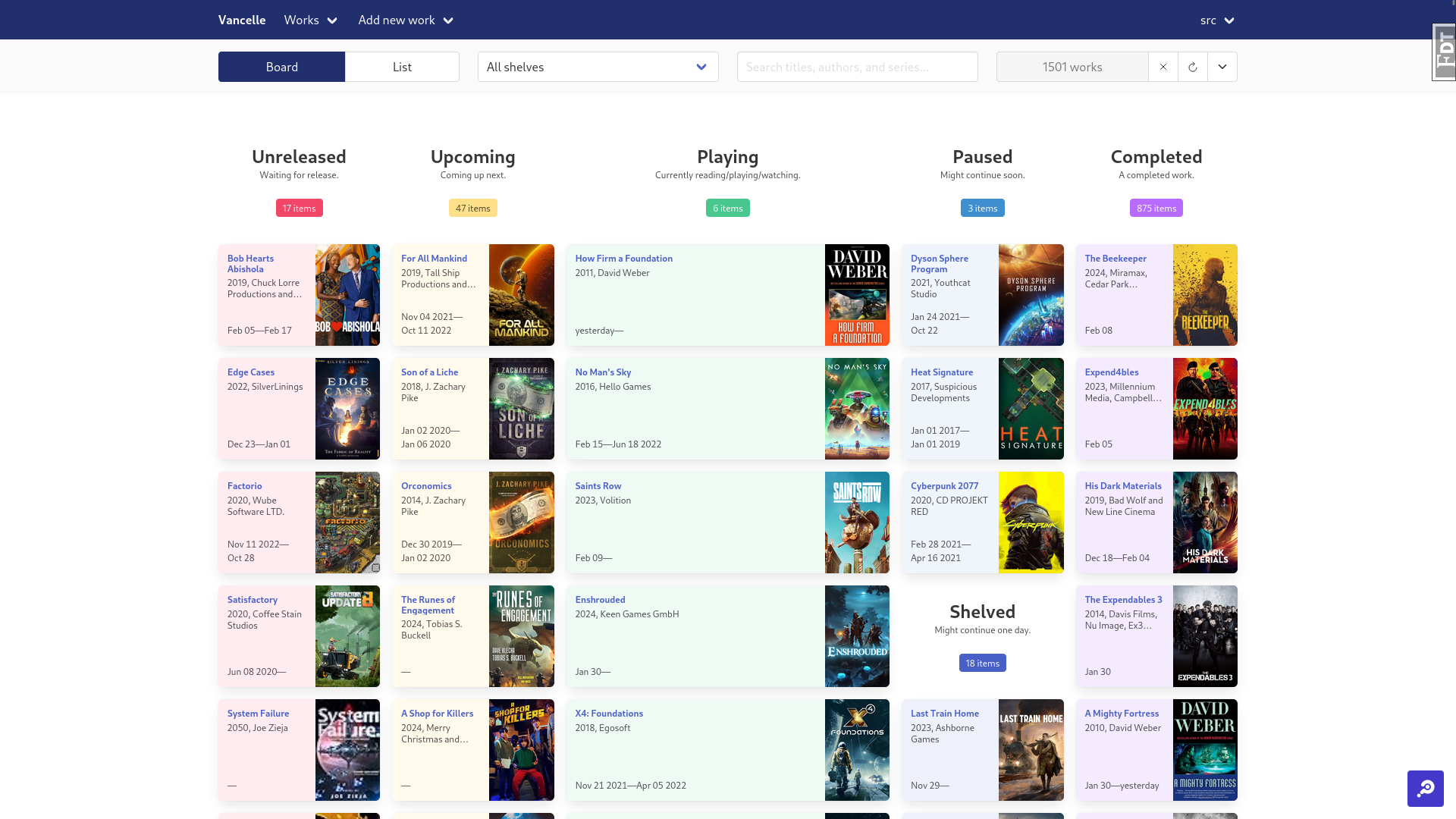
Recently, I had a lot of time away from work, and a set of related problems:
-
I use Goodreads to track all the books I read, but I couldn’t add non-traditional works like fics from Royal Road or Archive of Our Own to my lists.
- I looked at alternative sites like StoryGraph, but Goodread’s data exports don’t include all your data. Specifically, start dates and dates for multiple reads aren’t include in their CSV dump.
-
Video games are now spread across a lot of different storefronts. If a game wasn’t at the top of Steam’s recently played list, there’s a good chance I’d forget about it even if I was enjoying it.
-
There’s several sites out there for tracking films and tv I’ve watched, but I don’t want to spread my lists across multiple services. I’m also not really interested in my lists being public, or in writing reviews for other people to read—I just want to remember if I’ve already watched something!
-
The Notion spreadsheet I was using to fill some of these gaps was starting to creak. Manually entering names and looking up covers so my kanban board would look pretty was starting to get frustrating and time-consuming. I also couldn’t support entering multiple sets of dates for books I’d read more than once, or games I’d put down and come back to.
So, with these in mind, I set out to replace my spreadsheet with a full web application.
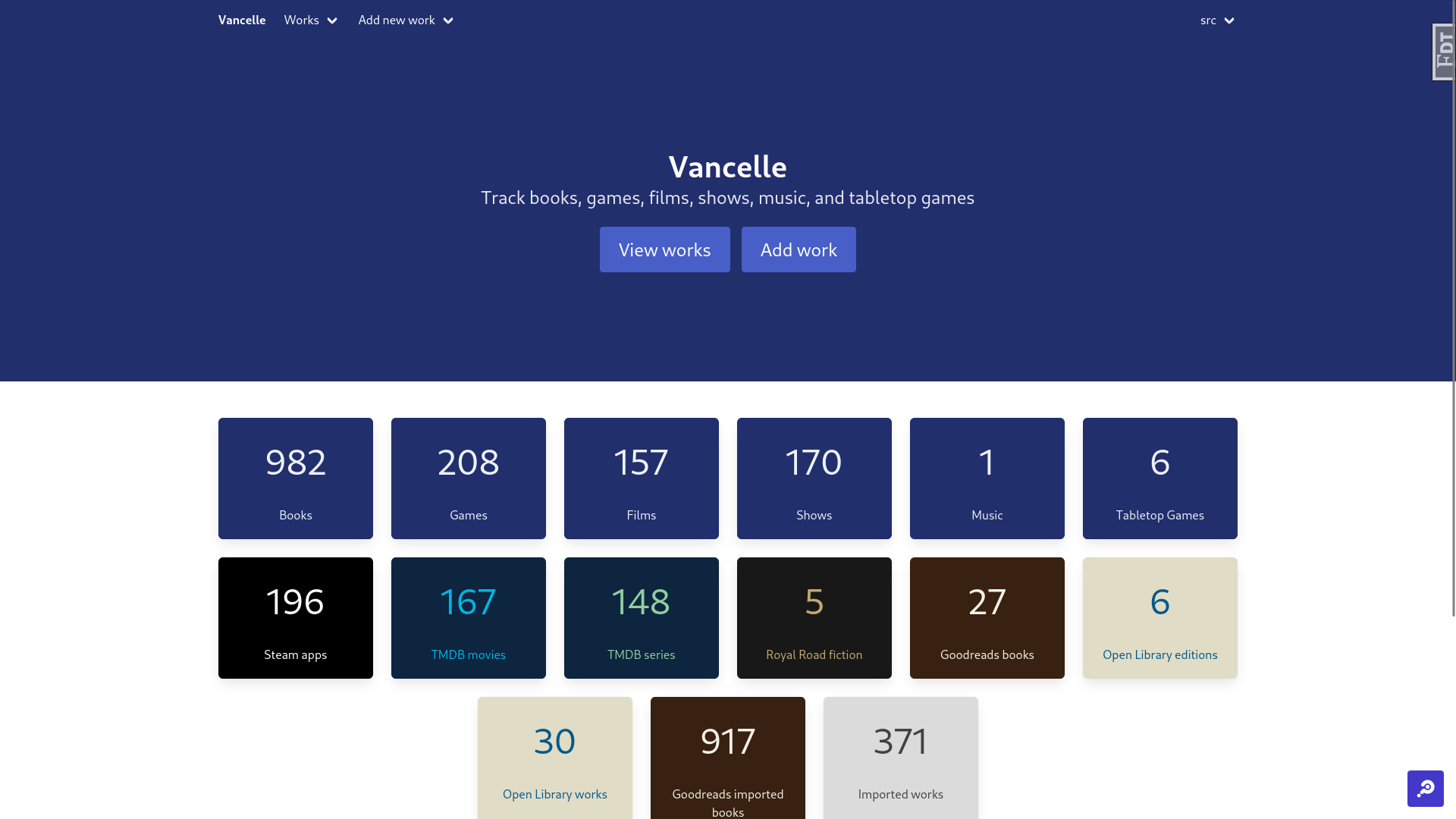
My data model went through lots of iterations, but I eventually settled on having “Works” (data about a work), “Remotes” (data about a work from an external source), and “Records” (a start and end date). Each work could have zero-or-more remotes and records. When displayed on screen, details about a piece of media were collected from the work and it’s remotes, with manually provided details from the work taking priority. This meant I could import data from multiple sources, and they could fill in gaps the other didn’t cover, and I could manually override any details I didn’t like (for instance, a lot of Steam games include ™ and ⓒ symbols in their titles).
This was also where I discovered my issues with Goodreads data exports. The first external source I added to my app was the ability to import data from my Goodreads account, both as that was the main service I wanted to replace and as the 700+ entries I had in there would be a great starting point for being able to build my app around real data. In the end, I actually ended up building a module that scraped HTML manually exported from Goodread’s infinitely scrolling books index so that I could include the dates I started reading a book.
A long time ago I’d always have a cloud server around to run various applications on (irc bouncers, a personal website, etc) but for a long time now I’ve been using exclusively cloud services to meet my needs. I didn’t really want to go to all this effort only to fuss over the ongoing costs of a cloud server — not so much due to the price, but the regular checking of if it was still something I needed. Instead, I got a spare Raspberry Pi from a friend, plugged that in next to my desk, and hosted the app on that. I originally used Dokku for this, but once I had multiple applications running I moved it over to a somewhat-less-powerful docker compose service.
It’s been really nice to get back some control over my own data—I dropped both Goodreads and a paid Notion subscription due to this! The Raspberry Pi has also worked out great, and once I had it I immediately started finding other uses for it. Having an always-online device that can run Syncthing to mediate files between my different personal devices (which are often not on at the same time) has been great, and allowed Obsidian to partially replace both Google Drive and Notion for me while keeping data within my own network. Tailscale was also really useful here, as it meant I could easily provision TLS certificates for my devices and serve everything over HTTPS, and I could reach my application when I left the house without having to expose the Raspberry Pi to the open internet.
If you’re interested in the source code, you can find it at borntyping/vancelle on Codeberg. It’s named after a librarian from the Old Kingdom series by Garth Nix.