Writing my own media catalogue, one year later
25 Sep 2025It’s been over a year since I started writing my own system to track media. To quickly recap, it’s a small Python webapp that replaced a mix of spreadsheets, notion tables, and Goodreads lists that I used to track games, films and books; and attempted to unify it all into a single database.
I made a few big changes over that time:
-
Two or three rewrites of a lot of the internal codebase.
-
I wrote my own micro Python-to-HTML library (inspired by hotmetal) that entirely replaced HTML templates. I was fully expecting to regret that later on, but it’s been nice enough to use that I’d happily use it again. It made it very easy to turn things into reusable components, and logic could use all the features of Python rather than the subset Jinja2 provides.
-
The app still uses HTMX in a few places, but I used it less and less as I rewrote things. It was usually much easier to do things the traditional web-app way with forms and full page reloads, and I didn’t have much need for interactivity.
-
-
Replaced Bulma with Bootstrap. Bulma was very pretty, but I kept reaching for elements I was used to from Bootstrap, and there was a major version upgrade that seemed to be missing some features that put me off it. Looking back at old screenshots, it’s definitely not quite so nice looking now.
-
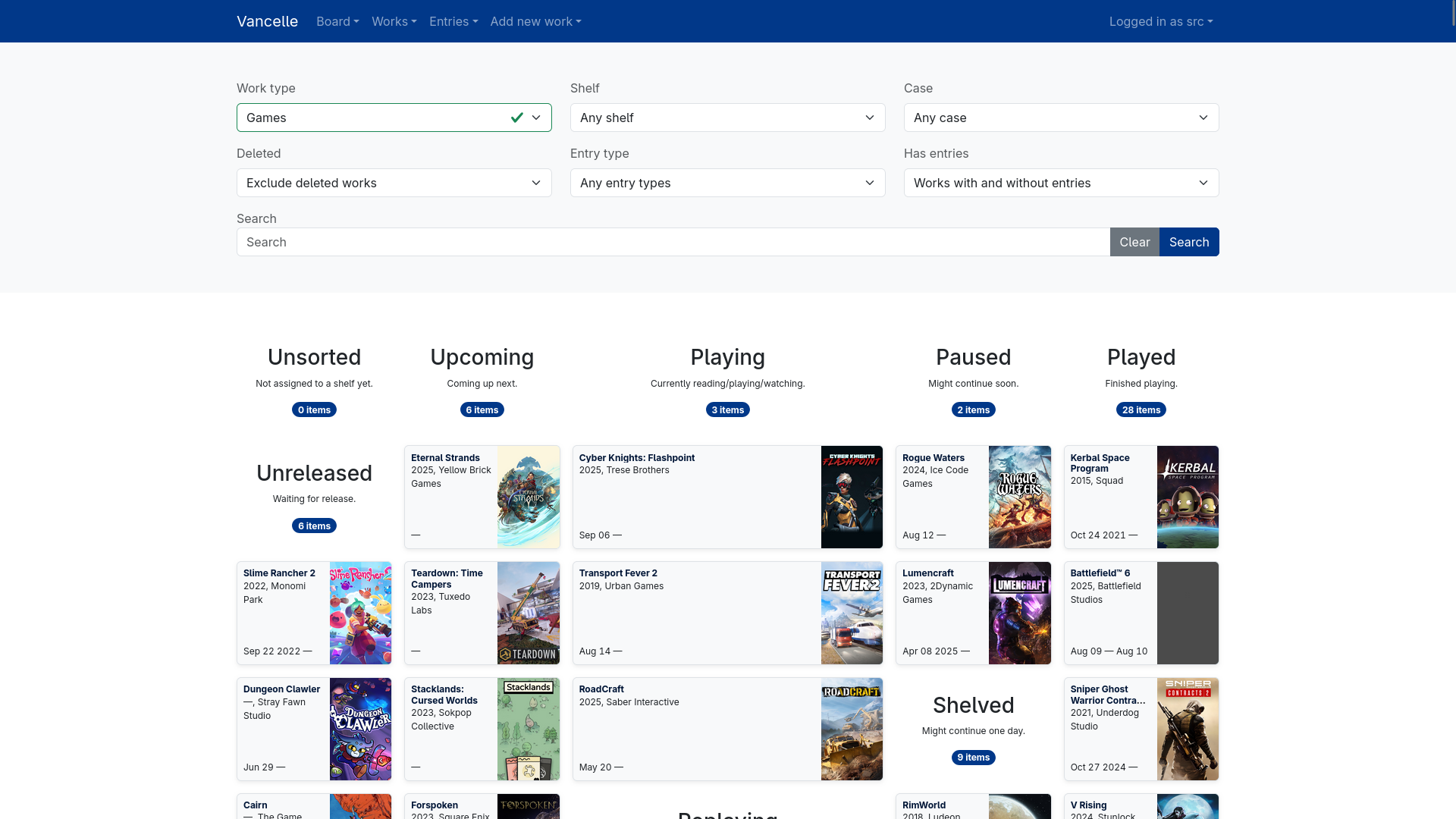
Added a lot of new categories for tracking where I’m at with media. I even ended up adding some meta-categories to group them up. It’s maybe ended up a bit overboard, but it seems to work for me and I don’t end up with too many items in the “now playing” groups (even when I have odd exceptions like games that can’t be completed). The meta-categories and categories I ended up with were Upcoming (upcoming, unreleased, undecided), Playing (playing, replaying, ongoing, infinite), Paused (Paused, Shelved), Completed (played, completed, abandoned), and Other (unsorted, reference, untouched).
-
I gave up on trying to do “REST” style URLs, and made different ways to view the same data entirely separate endpoints. Originally they had a toggle on the page to change a query parameter that selected a kanban-board style view or a simple table, and it ended up being much easier to maintain when I split the endpoints for them entirely, and shared some small bits of code for doing filtering.
There were quite a few changes I didn’t do, which I think are more interesting:
-
I never added support for other data sources. Even where I had multiple sources for the same type of media, I only ended up using one. (In this case I used Goodreads over OpenLibrary, even though the project was created to move my book lists out of Goodreads, because Goodreads had much better cover art images).
-
Lots of little buttons and features were broken and I never fixed them. There wasn’t much motivation to fix things when it was easy to work around them. I had some little buttons for things like marking I’d finished a book yesterday or today, and it was easy to work around them by manually inputting a date.
-
“Boring” work like adding indexes, debugging slow queries, and upgrading outdated libraries. The whole thing is running on a private network and I’m always going to be the only user, so I’m not very worried about maintained or security.
I stuck to my approach of writing an app that was entirely for myself. It was really nice to be able to entirely rewrite bits of it just because I wanted to, without worrying about breaking things or deadlines or the time spent. It ended up being a really relaxing project to work on at times.
If you want, you can take a look at the source at codeberg.org/borntyping/vancelle, but don’t expect it to come with instructions.